第二节.构造数组
新的数组可以使用Array创建例程中详述的例程来构建,也可以使用低级别的ndarray构造函数来构造:ndarray数组对象表示固定大小项目的多维同类数组。
1.索引数组
数组可以使用扩展的Python切片语法array [selection]进行索引。 类似的语法也用于访问结构化数组中的字段。可以参考:https://docs.scipy.org/doc/numpy-1.14.0/reference/arrays.indexing.html#arrays-indexing
2.n维数组的内部内存布局
类ndarray的一个实例由计算机内存的一个连续的一维片段(由数组拥有,或由其他对象)组成,并且将一个索引方案与N个整数映射到块中某个项目的位置。 指数可以变化的范围由数组的形状指定。 每个项目需要多少字节以及如何解释字节由与数组关联的数据类型对象定义。
一段存储器固有地是一维的,并且在一维块中布置N维阵列的项目有许多不同的方案。 NumPy是灵活的,而且ndarray对象可以容纳任何标准的索引方案。 在一个交叉的方案中,N维索引(n_0,n_1,...,n_ {N-1})对应于偏移量(以字节为单位):
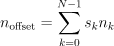
从与阵列关联的内存块开始。 这里,s_k是指定数组步长的整数。 列主要顺序(例如在Fortran语言和Matlab中使用)和行主顺序(在C中使用)只是特定类型的跨步方案,并且对应于可以通过跨步解决的内存:
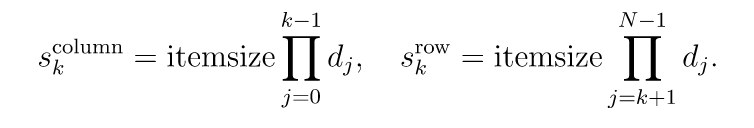
 = self.shape[j].
= self.shape[j].
C和Fortran顺序都是连续的,即单段内存布局,其中内存块的每个部分都可以通过索引的某种组合来访问。
虽然具有相应标志设置的C风格和Fortran风格的连续数组可以用上述步幅来寻址,但实际的步幅可能不同。 这可能发生在两种情况下:
- 如果self.shape [k] == 1那么对于任何合法索引index [k] == 0.这意味着在偏移量n_k = 0的公式中,因此s_k n_k = 0且s_k = self.strides的值 [k]是任意的。
- 如果一个数组没有元素(self.size == 0),没有合法的索引,并且从不使用步幅。 任何没有元素的数组可以被认为是C风格和Fortran风格的连续。
点1.意味着self和self.squeeze()总是具有相同的连续性和对齐的标志值。 这也意味着即使是一个高维数组也可以是C型和Fortran型同时连续的。
如果所有元素的内存偏移量和基本偏移量本身是self.itemsize的倍数,则认为数组是对齐的。
注意
点(1)和(2)默认还没有应用。从NumPy 1.8.0开始,只有在构建NumPy时定义了环境变量NPY_RELAXED_STRIDES_CHECKING = 1,才能一致地应用它们。最终这将成为默认。
你可以通过查看np.ones((10,1),order ='C')。的值来检查当你的NumPy是否被启用了。flags.f_contiguous。如果这是真的,那么你的NumPy放松了大踏步查询启用。
警告
它通常不会保持self.strides [-1] == self.itemsize为C型连续数组或self.strides [0] == self.itemsize为Fortran型连续数组为true。
除非另有说明,新的ndarray中的数据按行 - 主(C)顺序排列,但是,例如,基本数组切片通常会以不同的方案生成视图。
注意
NumPy中的几种算法可以在任意的步长阵上工作。但是,有些算法需要单段数组。当一个不规则序列的数组被传入这样的算法时,会自动进行复制。